A (not so short) summary of the Google Bigtable paper
I spent some time to read this interesting paper and took some notes for my own reference. Thought of sharing it here in case it might be useful for others too.
Introduction
- Title: Bigtable: A Distributed Storage System for Structured Data
- Authors: Fay Chang, Jeffrey Dean, Sanjay Ghemawat, Wilson C. Hsieh, Deborah A. Wallach Mike Burrows, Tushar Chandra, Andrew Fikes, Robert E. Gruber ({fay,jeff,sanjay,wilsonh,kerr,m3b,tushar,fikes,gruber}@google.com)
- Link: https://static.googleusercontent.com/media/research.google.com/en//archive/bigtable-osdi06.pdf
Bigtable is a distributed storage system for managing structured data that is designed to scale to a very large size: petabytes of data across thousands of commodity servers.
Different application within Google demands different requirements in terms of data size, throughput, latency, etc. and Bigtable can successfully cater to these requirements. It is important to note that this paper was released in 2006 and by the time of writing this article they must have developed superior solutions (e.g. Spanner) which might have adopted by the majority of applications. Nevertheless, this paper is still a great read offering a lot of learning.
Description
Data model
A Bigtable is a sparse, distributed, persistent multi-dimensional sorted map. The map is indexed by a row key, column key, and a timestamp; each value in the map is an uninterpreted array of bytes.
(row:string, column:string, time:int64) → string
Rows
Row keys are arbitrary strings up to 64KB in size. Every read-write for a single row key is atomic. Data is maintained in lexicographic order by row key. The row range for a table is dynamically partitioned. Each row range is called a tablet, which is the unit of distribution and load balancing.
Column families
Column keys are grouped into sets called column families, which form the basic unit of access control. All data stored in a column family is usually of the same type (data in the same column family compressed together). It is intended to keep the number of distinct column families in a table be small (in the hundreds at most), and that families rarely change during operation. In contrast, a table may have an unbounded number of columns.
A column key is named using this syntax: family:qualifier. Access control and both disk and memory accounting are performed at the column-family level.
Timestamps
Each cell in a Bigtable can contain multiple versions of the same data; these versions are indexed by timestamp. Timestamps are 64-bit integers. Timestamps can be auto-generated by Bigtable which is basically represents real-time in microseconds or it can be manually provided by the applications. Different versions of a cell are stored in decreasing timestamp order so that the most recent versions can be read first.
For better management of versions, it is possible to configure garbage collection of older versions by specifying either to keep last n versions or to keep versions of specific time duration (e.g. a week or a month).
API
Bigtable API provides functions to manage the table, column families, and other metadata. One of the important aspects of the API is its optimized scanning capabilities while retrieving data. There are several mechanisms for limiting the rows, columns, and timestamps produced by a scan. For example, it is possible to restrict the scan to only produce columns matching specified regex or to produce only those records whose timestamp falls under specified range.
As mentioned earlier read/modify operations on a single row key is atomic however general transactions across row keys are not supported.
Bigtable can be used along with MapReduce. There are wrappers available that allow Bigtable to be used as a source or target of MR jobs.
Building blocks
Uses the distributed Google File System (GFS) to store log and data files.
The Google SSTable file format is used internally to store Bigtable data. An SSTable provides a persistent, ordered immutable map from keys to values, where both keys and values are arbitrary byte strings.
Bigtable relies on a highly-available and persistent distributed lock service called Chubby for variety of tasks which requires distributed locking. If Chubby becomes unavailable for an extended period of time, Bigtable becomes unavailable.
Implementation
Major components
- Client library: linked to every client.
- Multiple tablet servers: Each tablet server manages a set of tablets (typically somewhere between ten to a thousand tablets per tablet server). It handles read and write requests to the tablets that it has loaded, and also splits tablets that have grown too large. Tablet servers can be dynamically added/removed from the cluster to scale the cluster to meet the workload requirement.
- A master server: Responsible for assigning tablets to tablet servers, detecting the addition and expiration of tablet servers, balancing tablet-server load, and garbage collection of files in GFS and handling schema changes such as table and column family creations.
Client data does not move through the master: clients communicate directly with tablet servers for reads and writes. Because Bigtable clients do not rely on the master for tablet location information, most clients never communicate with the master keeping the load on the master very low in practice.
Initially, each table consists of just one tablet. As a table grows, it is automatically split into multiple tablets, each approximately 100-200 MB in size by default.
Tablet location
Tablet location information is stored in a three-level hierarchy as shown below:
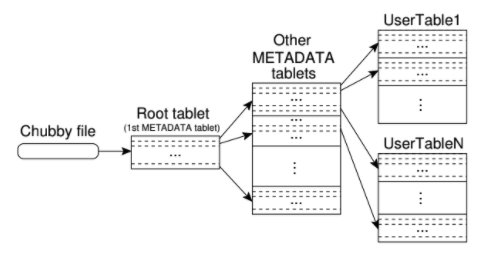
Figure credit: taken from the original paper
- Chubby file: A file stored in Chubby that contains the location of the root table.
- Root tablet: Contains the location of all tablets in a special METADATA table.
- METADATA tablets: Contains the location of a set of user tablets.
The root tablet is just the first tablet in the METADATA table, but it is never split to ensure that the tablet location hierarchy has no more than three levels
The client library caches tablet locations. If the client does not know the location of a tablet, or if it discovers that cached location information is incorrect, then it recursively moves up the tablet location hierarchy.
Tablet assignment
Each tablet is assigned to one tablet server at a time. The master keeps track of the set of live tablet servers, and the current assignment of tablets to tablet servers, including which tablets are unassigned.
Tracking tablet servers
When a tablet server starts, it creates a uniquely-named file in a specific Chubby directory and acquires a lock on it. The master monitors this directory to discover available tablet servers.
Detecting non-operational tablet server
The master periodically asks each tablet server for the status of its lock. If the tablet server reports that it has lost its lock or if the master is unable to reach a tablet server, then it tries to take a lock on that server’s file. If the lock is successful indicating that Chubby is live, that means that either the tablet server is not able to reach Chubby or the server is down. In this case, the master deletes the server’s file and moves its tablets to the pool of unassigned tablets which makes these tablets eligible for reassignment to another tablet server.
What if the master is unable to reach Chubby?
In that case, the master will kill itself so another node is elected as master. Note that this doesn’t affect the overall system much as master failures do not change the assignment of tablets to tablet servers. Neither does it affect client connections as clients directly interact with tablet servers (as mentioned in the earlier section clients have their own tablet location cache).
What happens when a new master is started?
It executes the following steps:
- Grabs a unique master lock in Chubby which prevents concurrent master instantiation
- Scans the server directory in Chubby to find the current active tablet servers
- Communicate with each live tablet server to discover what tablets are already assigned to them.
- Scans the METADATA table to learn the set of tablets. Whenever it encounters a tablet that is not already assigned, it adds the tablet to the pool of unassigned tablets making them eligible for assignment to some tablet server.
Handling the changes in the existing set of tablets
The set of existing tablets can change in the following scenarios:
- A new tablet is created
- An existing tablet is deleted
- Two existing tablets are merged to form a larger tablet
- An existing tablet is split into two smaller tablets
The first three changes are initiated by the master hence it is always aware of these changes. The fourth scenario is a special one as that is initiated by the tablet server holding a particular tablet. The tablet server records the information of the newly created tablet in the METADATA table and also notifies the master about the split. If the notification is lost due to any reason, the master will detect the new tablet whenever it will ask the tablet server to load the tablet which is now split.
Tablet serving
The following figure shows the storage representation of a tablet:
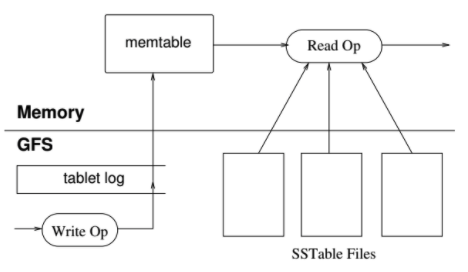
Figure credit: taken from the original paper
- Tablet log: All the updates are written to a commit log that stores redo records.
- Memtable: A sorted buffer that stores the recently committed updates in memory.
- SSTables: Older updates are stored in a sequence of SStables which are persisted on GFS.
How a tablet is recovered by a tablet server?
It reads the tablet metadata from METADATA table which contains the list of SSTables which contains the tablet data and a set of pointers into any commit logs that may contain data for the tablet. The server reads the indices of the SSTables into memory and reconstructs the memtable by applying all of the updates that have been committed since the redo points.
Serving write requests
The server authorizes the sender (list of permitted writers is retrieved from a Chubby file), and the write operation is written to the commit log. When the write is committed, its content is inserted into the memtable.
Serving read requests
The sender is authorized by the server and the read operation is executed on a merged view of the sequence of SSTables and the memtable. Note that the SSTables and the memtable are lexicographically sorted data structures hence the merged view can be formed efficiently.
Compactions
As write operations execute, the size of the memtable increases. When the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS.
The above process is called minor compaction which reduces the memory usage of the tablet server and also reduces the amount of data that has to be read from the commit log during recovery if the server dies.
The minor compaction will keep on creating a lot of SSTable and this means the read operation will have to merge the updates from an arbitrary number of SSTables. To solve this periodically a merging compaction (a.k.a. major compaction) is performed in the background which reads the contents of a few SSTable and the memtable, merges them, and writes them to a new SSTable. The input SSTables and the memtable can be discarded as soon as the compaction is finished
It is important to note that the SSTables created by minor_compactions also contain deleted entries to keep track of delete operations. These entries are removed by the major compaction along with all other modification entries for the same record (as the record is deleted from the table).
Left-over sections
The paper contains some more sections covering additional refinements, performance readings, and real-life use-cases which are very interesting to read. However, I am skipping them from this article as I don’t find them necessary to be added to this summary.
References: